
Author: Steven Palayew
Published: 17 Mar 2023
Description: Improving our notification filtering model
ML Model Update 2 (Mar 13-17)
In my previous blog post, I discussed how I was able to expand my training set with the help of GPT3 in order to address the overfitting issue we were previously facing, and ultimately develop a more performant notification filtering model. Noting the improved performance of this model, today we will be taking a deeper dive into where it performs well, and where it performs poorly in order to be able to better understand its strengths and weaknesses before deployment.
First, circling back to the 22 datapoint test set which as I mentioned in my previous post the model was 90.9% accurate on, we generate a more comprehensive summary of classification performance on this test set below:
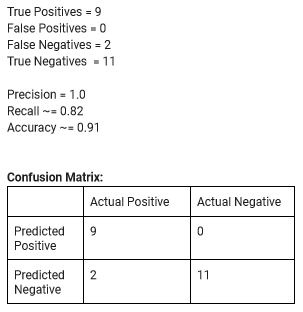
These results indicate that our model is slightly biased towards classifying messages as non-urgent. This could potentially be addressed with threshold moving (ie. classifying messages as urgent if the model is less than 50% sure), however before committing to this, we wanted to see how it performed on a test set that was generated by another group member whose writing style the model would not have seen during training.
Taking a look at the model’s performance on a test set made up of 17 messages generated by another group member, the results are as follows:
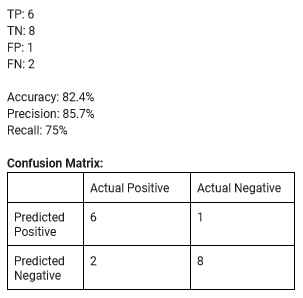
Here, the gap in precision and recall begins to close. Furthermore, of the false negatives, the model’s confidence that the messages were urgent were 0.15 (15%) and 0.36 (36%) approximately. For reference, the model was 33% confident that “Man I’m so tired”, a clearly non-urgent message, was urgent. It was therefore ultimately decided to not conduct threshold moving, and to continue to consider messages as urgent if and only if the model was over 50% confident of this.
Although there was a notable drop in performance between my test set and my teammate’s test set, this is to be expected as the model was trained on my writing style. If we extend this project, it would therefore likely be a good idea to have multiple people generate training data such that the model can generalize better. With that said, the model performance is still respectable, and was unanimously considered by the team to be more than adequate as a proof of concept. We therefore decided to use this as our final model for our symposium demo.
Going forward, something else we may want to consider is that training on synthetic messages may make the system prone to labeling spam messages as urgent. This can be illustrated by looking at some of the synthetic urgent messages, which are written very similarly to how a spam message would be written:

Potentially the best way to address this would be to use a two stage approach, with one notification filter classifying messages as spam vs not spam, and a second filter classifying them as urgent vs non-urgent. This is because classifying messages as spam is a very commonly studied problem in machine learning and it should not be overly difficult to train or use a pre trained classifier for this task, and inference time as of now is quite fast (well under 1 second) and therefore adding a second filter should not be a big concern in that respect.
Another thing we may want to try going forward is using the new GPT4 to generate spam messages, as this new model is a large upgrade over GPT3 (more info), and it would be exciting to see what improvements it could bring to this project!
I hope you enjoyed my two part blog series! If you have any questions, don’t hesitate to reach out to ringifywaterloo@gmail.com , or my personal address spalayew@gmail.com!